Author: Giovanni Collazo
-
Notes #12
Guide to Implement an SSH Client Using Golang In Golang, the crypto/ssh package provides functionality for implementing an SSH client. tailspin tailspin works by reading through a log file line by line, running a series of regexes against each line. The regexes recognize patterns you expect to find in a logfile, like dates, numbers, severity…
-
Notes #12
Python errors as values: Comparing useful patterns from Go and Rust A thrown error interrupts the control flow, propagating down the call stack until it’s caught. If it isn’t caught then the program cashes. A big problem with this approach is a lack of clarity on where an error might occur. Litestream: Cron-based backup Sometimes…
-
Notes #11
Flappy Dird: Flappy Bird implemented in MacOS Finder 5 simple tips to making responsive layouts the easy way Modern CSS Resets A (more) Modern CSS Reset CSS Tools: Reset CSS My Custom CSS Reset Being Picky about a CSS Reset for Fun & Pleasure Why you should never use px to set font-size in CSS…
-
Notes #10
semgrep Lightweight static analysis for many languages. Find bug variants with patterns that look like source code. Cómo imprimir libritos artesanales A7 Text Fragments API Rule of least power Computer Science in the 1960s to 80s spent a lot of effort making languages that were as powerful as possible. Nowadays we have to appreciate the…
-
Notes #9
Using Strace to Trace Linux Syscalls Tailscale: Subnet routers and traffic relay nodes …you can set up a “subnet router” (previously called a relay node or relaynode) to access these devices from Tailscale. Subnet routers act as a gateway, relaying traffic from your Tailscale network onto your physical subnet. Subnet routers respect features like access…
-
Notes #8
MindAPI Organize your API security assessment by using MindAPI. It’s free and open for community collaboration. SSL Pinning Bypass For Android Using Frida This approach enables security researchers to audit Android mobile apps that use certificate pinning. Basically it will allow you to MITM even if the app has pinning enabled. Very cool! Better Builds…
-
Notes #7
Infinite Mac Infinite Mac is a collection of classic Macintosh system releases and software, all easily accessible from the comfort of a (modern) web browser. From React to htmx on a real-world SaaS product: we did it, and it’s awesome! Where Hollywood’s Printed Props Are Made! File distribution over DNS: (ab)using DNS as a CDN…
-
Notes #6
Mac SE Easter Egg On The Metal Podcast I just learned about this podcast and it’s great. A lot of great and interesting interviews. Must listen. WordPress: Status update on the SQLite project This brings support for SQLite in WordPress core. In the near future you will be able to deploy WordPress backed by a…
-
Notes #5
Hypermedia Systems Book This books describes the approach I’ve been using to build modern web apps for the last few years. This is the same approach I used back when I was just getting started in web development around 2010. The books is available for free online but please consider buying a copy to support…
-

Running a Bug Bounty Program Without Spending a Fortune
Bug bounty programs have emerged as a crucial cybersecurity measure, allowing organizations to harness the skills of the security community in identifying and resolving vulnerabilities before malicious actors can exploit them. While many opt for popular bug bounty platforms, these can come with hefty price tags. In this blog post, we’ll explore the steps to…
-
Notes #4
The Code Review Pyramid Its intention is to help putting focus on those parts which matter the most during a code review (in my opinion, anyways), and also which parts could and should be automated. The easiest way to speed up Python with Rust If you want to speed up some existing Python code, writing…
-
Notes #3
The Xerox Smalltalk-80 GUI Was Weird At first glance, this looks incredibly similar to something like the desktop of the Apple Lisa or early Mac OS. It’s easy to see why people might think that Apple sort of stole the graphical user interface from it’s rich neighbor Xerox. It’s not true, though. The first thing…
-
Notes #2
NetNewsWire: Manage and Use Article Themes Recently learned that you can change the theme in NetNewsWire. There’s even a theme directory with lot of options to choose from. I’m currently using Promenade from the built-in selection, it looks great. Status of Python Versions Very nice and up to date graph of past, current and future…
-
Notes #1
I’m trying to post more regularly so I stole this weeknotes idea from Simon Willison’s Weblog. The plan is to share articles, videos, books and things I learn. Here’s the first one. Imaginary Problems Are the Root of Bad Software The human brain however, after billions of years of evolution, is quite talented at keeping…
-
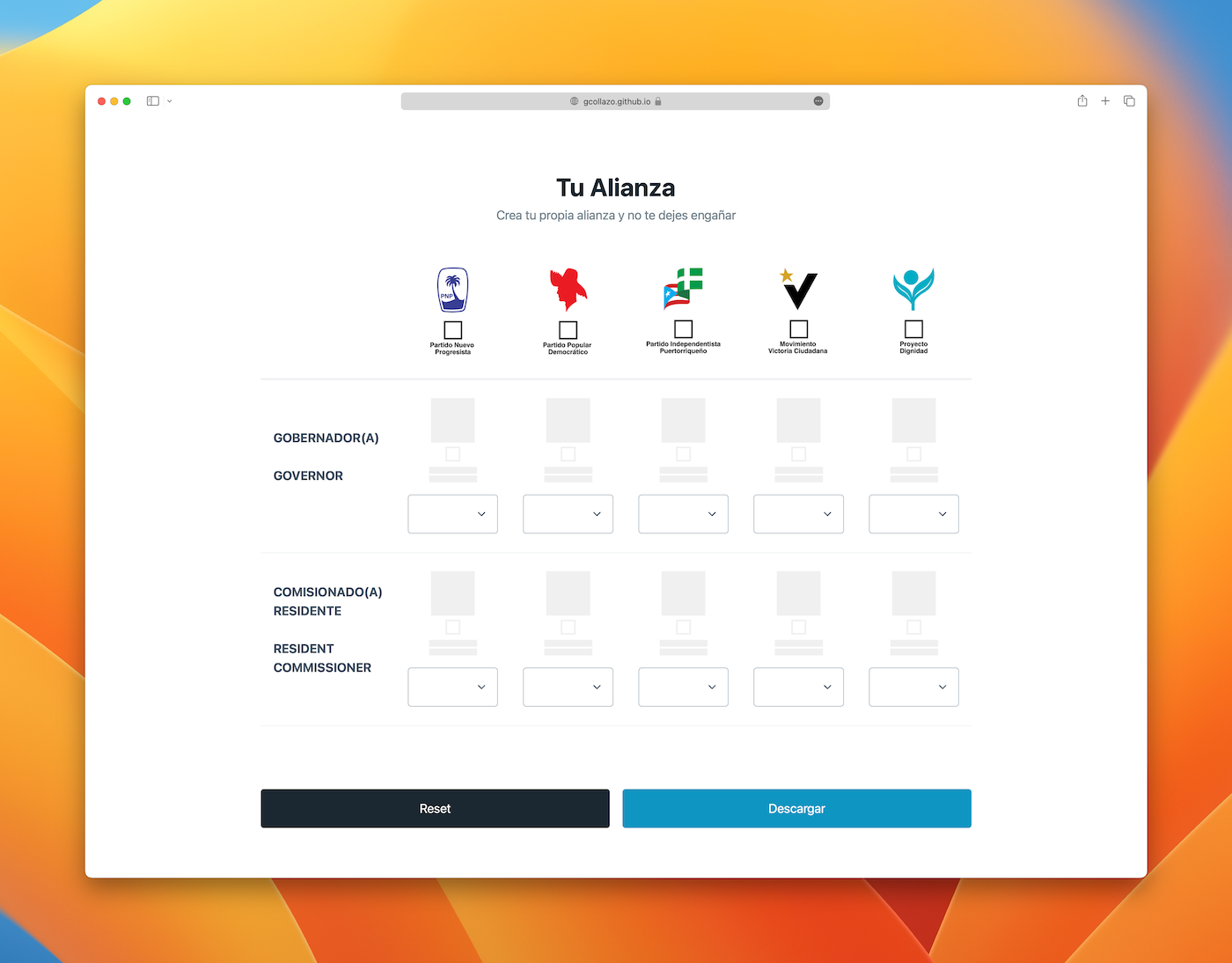
Tu Alianza
En días reciente hemos visto mucha discusión sobre el tema de las alianzas. Se han hecho muchos argumentos en contra, todos muy flojos pero quizás el mas bobo es que sería confuso para el elector. Para demostrar que no es confuso na’ y para trolear un poco fue que cree esta pagina. Ahora puedes crear…
-

Favorite Tiny Desk Concerts
Ordered alphabetically:
-
Upvote Beluga 🐳
Beluga 🐳 just launched on Product Hunt. Please take a minute to upvote. UPVOTE HERE Thanks!!!
-

Después de Gasolina Móvil
Hace mas de siete años y sin avisar me llamó Arnaldo para contarme de un invento que tenía. La idea era simple, vamos a hacer un app para que la gente pueda pagar la gasolina. Inmediatamente me pareció una buena idea. Estaba seguro que los consumidores les encantaría poder pagar en la bomba. Ahí, en…
-
Clear explanation of Rust’s module system
This blog post helped me clear my understanding of how Rust’s module system works. This is required reading to all beginners. Rust’s module system is surprisingly confusing and causes a lot of frustration for beginners. In this post, I’ll explain the module system using practical examples so you get a clear understanding of how it…
-

El Lenguaje de Programación Perfecto
En mi trabajo escribo principalmente TypeScript sobre Node.js y aunque no es mi lenguaje favorito, no me molesta, tiene muchas cosas buenas. Para el tipo de proyecto que trabajo, el tener un “type system” es altamente valioso. También escribo bastante Python (de mis lenguajes favoritos) para “scripts” locales y otras cosas que no necesariamente terminan…